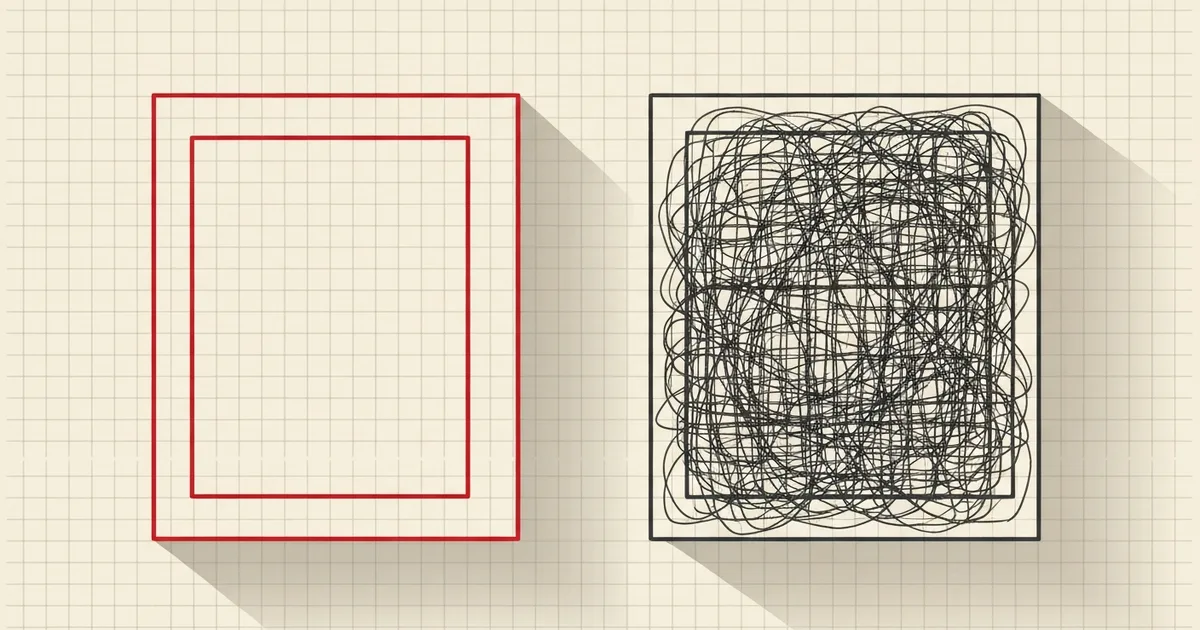
You wrote a resume. A robot read it first. That's the part most people skip past, and it's the part that decides whether a human ever sees your name.
An ATS-friendly resume format is a layout that an Applicant Tracking System can fully parse: a single column, real selectable text instead of images, standard section headings, and no tables or text buried in headers or footers. Get that right and your work history lands in the right database fields. Get it wrong and your job title quietly becomes blank.
Applicant Tracking Systems are mainstream in enterprise hiring now. Commonly cited industry figures suggest that nearly all Fortune 500 companies run one, and that around 70 percent of large companies and roughly 75 percent of recruiters use an ATS or a similar recruiting tool. Those are directional, secondary-source numbers rather than an audited census, so treat them as the shape of the thing, not the precise measurement. The shape is enough: if you apply to big employers, software reads you before a person does.
The resume you designed for human eyes and the data the parser extracts are two different documents. The format's whole job is to keep them in sync.
What an ATS actually does to your file
An Applicant Tracking System is not a spam filter that throws resumes away. It's a database with a parser bolted to the front. When you upload a file, the parser tries to convert your visual document into structured fields: name, email, phone, each job title, each employer, start and end dates, skills, schools, degrees.
That conversion is the fragile step. A PDF or DOCX is a layout format. It describes where ink sits on a page, not what each piece of text means. So the parser reads the text stream, guesses at structure from spacing and headings, and writes its guesses into columns. When the layout fights the parser, the guesses go bad.
Parse, then rank, then screen
After parsing, most systems rank and sort candidates rather than auto-rejecting them on resume content alone. In one 2025 recruiter sample, 92 percent of ATS users interviewed said their system does not auto-reject based on resume content. That's a small, vendor-published interview group, not a population rate, so hold it loosely. But the direction matters: the early cut is usually done by knockout questions the employer sets, things like work authorization, location, or years of experience, not a secret resume-scoring gremlin.
So the popular line that "75 percent of resumes are rejected by the ATS" is not supported by peer-reviewed evidence. It's repeated everywhere and sourced almost nowhere. The real risk is duller and more common: your resume parses badly, your skills land in the wrong field, and a recruiter searching for "Python" never surfaces you because your skills section was a two-column table the parser flattened into mush.
Where the major systems live
The names you'll meet are Workday, Taleo (Oracle), Greenhouse, Lever, iCIMS, and Ashby. Reliable public market-share percentages for these vendors are thin, so anyone telling you one "dominates" with a hard number is guessing. What's defensible is that enterprise buyers now choose on workflow, integrations, analytics, and AI features, which is exactly why those vendors compete hard in the large-employer segment. Each ships its own parser, and each parser has its own quirks. A layout that sails through Greenhouse can still trip Workday.
Why one resume behaves differently across systems
There's no shared parsing engine behind these products. Each vendor wrote its own extraction logic, tuned it on its own corpus of resumes, and updates it on its own schedule. So the same file can produce a clean read in one portal and a scrambled one in the next. A few practical consequences fall out of that.
- Some Workday application flows ask you to upload a file and then re-key the same fields into a form, because the company doesn't fully trust the parse. You're effectively the backup parser.
- Greenhouse and Lever lean on recruiter-driven keyword search over the parsed pool, which means a skill that lands in the wrong field is functionally invisible even if the recruiter would have loved it.
- iCIMS and Taleo are older lineages with deep enterprise customization, so the same vendor can behave differently between two employers depending on how each configured it.
You can't test against every one of these before you apply, and you usually don't even know which system a given employer runs. That uncertainty is not a footnote. It's the core reason the format rules below are written conservatively: you're building for the strictest plausible parser, because you don't get to pick which one reads you.
The format rules that pass in 2026
The supportable, repeatable advice has not changed much, because the failure modes haven't. Tables, text boxes, multi-column layouts, and graphics raise the risk of misread or lost structure during parsing. Plain DOCX is described across the source material as the safest format. Build around those facts.
- One column. Always. Multi-column layouts force the parser to decide reading order, and it often guesses wrong, splicing your job title onto the wrong company. A single top-to-bottom column reads in the order you intend.
- Real text, never images. If you can't click and select a word with your cursor, neither can the parser. Skills rendered as little icon graphics are invisible. A logo with your name baked in is invisible.
- Standard section headings. Use
Experience,Education,Skills,Projects. Clever headers like "Where I've Made Noise" mean the parser can't tag the block, so it gets dumped into a generic bucket or dropped. - Nothing important in the header or footer. Many parsers ignore the header and footer region entirely. Putting your phone and email up there is the single most common way people lose their own contact details.
- No tables for layout. A skills grid or a two-column date layout built from a table can collapse into a single run of text. "Python SQL 2019 2022 Senior Engineer Acme" is not a row a recruiter can search.
- Standard fonts, real bullet characters. Stick to common system fonts. Use actual bullet list formatting, not a dash or an asterisk you typed by hand, and definitely not custom glyphs.
- Dates in a consistent, obvious pattern. Pick
MMM YYYYlikeJan 2021and use it everywhere. Mixed date styles confuse the date extractor and your tenure math comes out wrong. - File name and file type that behave. A text-based PDF exported from a word processor, or a clean DOCX, both work. A PDF that's actually a scanned image of a printed page is a picture, and the parser reads nothing.
One dry note. People love to ask whether they should stuff white keywords in white text to game the parser. Don't. Recruiters open the file, see a wall of hidden text when they highlight it, and it reads exactly as desperate as it is.
The smaller rules that quietly matter
The eight above are the load-bearing ones. A handful of smaller habits prevent the annoying edge-case failures that don't show up until something breaks.
- Spell out and repeat acronyms. Write "Search Engine Optimization (SEO)" once, then use SEO. Keyword search matches strings, so a recruiter querying the long form and one querying the short form should both find you.
- Don't merge job title and company on one line with a divider glyph. "Senior Engineer | Acme Cloud" sometimes parses as a single field. Keep title and employer on separate lines or in a clear, plain pattern.
- Avoid putting dates only in a right-aligned tab column. If that alignment came from a table or tab stop the parser flattens, your dates drift away from the job they belong to.
- Keep the file name plain. Something like
Ashley-Carter-Resume.pdfis fine. Spaces and odd characters mostly survive now, but plain is one less variable. - One resume per file. Don't combine a resume and cover letter into a single PDF for a resume upload field. The parser expects a resume and gets confused by two documents stapled together.
What parsers keep versus what they silently drop
Here's the asymmetry nobody warns you about. When a parser keeps your data, you see nothing. When it drops your data, you also see nothing. There's no error message. Your resume looks perfect on your screen and arrives in the database with holes.
Usually kept
- Plain paragraphs of body text in a single column.
- Standard headings followed by their content.
- Email and phone written inline in the document body.
- Job entries shaped as title, company, dates, then bullets.
- A flat, comma or line-separated skills list.
Frequently mangled or lost
- Text inside headers and footers, including contact info.
- Anything inside a table cell, especially multi-column tables.
- Text inside text boxes, shapes, or sidebars.
- Skills or names rendered as images or icons.
- Multi-column reading order, which the parser may scramble.
- Special characters and non-standard bullets.
A worked example. Say your beautiful template puts a left sidebar with Skills and Languages, and a right main column with Experience. To you it's clean and modern. To the parser it's two text streams it has to interleave. Best case, your skills end up after your work history in a jumble. Worst case, the sidebar is a text box and the whole thing vanishes. You never find out, because the rejection looks identical to "we had stronger candidates."
Silence is the failure mode. A misparsed resume produces no warning, just an application that quietly underperforms a worse candidate with a plainer file.
A before-and-after, in plain text
To make the failure concrete, here's what a two-column sidebar template can turn into once the parser flattens both streams into one text run. The author intended a tidy skills box on the left and an experience column on the right. The extracted text comes out like this.
Skills Go PostgreSQL Redis Senior Backend Engineer Acme Cloud Mar 2021 Languages English German Cut median API latency from 480ms to 110ms Nov 2024
Read it back. The skill "Redis" now sits next to "Senior Backend Engineer," the start date "Mar 2021" got separated from its end date, and "Languages" wandered into the middle of a job description. A recruiter searching "PostgreSQL" might still hit it, but a system trying to compute your tenure at Acme Cloud has the start and end dates split by an unrelated language list. Nothing errored. The file looked gorgeous on screen. The database just got nonsense.
The single-column version of the same content extracts in the order you wrote it, dates stay attached to their jobs, and skills sit in one clean run. Same information, one structural choice apart, completely different outcome.
A pre-submit checklist and the common mistakes
Before you upload anything to a portal, run this list. It takes two minutes and it catches the failures that otherwise stay invisible until your application underperforms.
- Open the PDF, press select-all, copy, and paste into a plain text editor. Does it read top to bottom in the right order?
- Is your email and phone present in that pasted text, in the body, not stranded in a header?
- Are your section headings the standard words, spelled normally?
- Did any skill or date land next to the wrong job after pasting?
- Is every job entry shaped as title, company, dates, then bullets?
- Are all dates in one consistent format?
- Is it actually selectable text, not a scanned image of a page?
And the mistakes that show up over and over, ranked roughly by how often they bite people:
- Contact info in the header region. Feels tidy, gets dropped, and you never hear from anyone.
- A two-column or sidebar template. The number-one cause of scrambled output, and the prettiest templates are the worst offenders.
- Skills as an icon grid. Five little logos for your tools read as zero skills.
- A scanned or image-only PDF. Common when someone prints, signs, and rescans. The parser sees a photograph.
- Creative section names. "My Journey" instead of "Experience" leaves the parser with no label to attach.
- Keyword stuffing in white text. Detectable, off-putting, and increasingly flagged.
AI screeners changed the input, not the fragility
By 2025 and 2026, AI in recruiting stopped being experimental. A 2026 Lever piece frames AI and automation as table stakes in modern ATS evaluation, covering candidate matching and ranking, interview transcription and summarization, and predictive analytics. Bullhorn, citing the 2026 GRID Industry Trends Report, says 78 percent of staffing firms growing revenue by more than 25 percent have AI tools embedded in their ATS. That last figure is specific and attributable, but it describes fast-growing staffing firms, not every employer, so don't stretch it.
One 2026 summary also reports AI adoption across HR tasks jumping to 43 percent in 2025 from 26 percent in 2024, citing SHRM's State of Recruiting 2025. Since the original SHRM text isn't in front of me, treat that as a secondary citation. The honest read across all of it: AI now sits inside ATS ranking, matching, and summarization. It is not, in the cited material, a universal final-rejection robot.
And here's the catch that matters for format. An LLM-based screener still starts from parsed, structured fields. It summarizes and matches against the data the parser extracted, not the pretty layout you designed. So a fancier AI on top of a fragile parser doesn't save you. If the parse loses your job title, the AI is reasoning about a candidate with a missing job title. Smarter reader, same broken input.
The deeper problem: you're guessing
Every rule above is real and worth following. But notice what you're actually doing when you apply them. You're hand-formatting a layout document and hoping an unknown parser, owned by an employer you can't see, reads it the way you meant. You get no receipt. No confirmation. No field-by-field readout of what landed.
That's the structural flaw. The resume was designed in the 1480s as a letter and standardized as a one-page printed sheet for the photocopier era. We then asked software to reverse-engineer meaning out of a document built for ink. The parser is doing forensic reconstruction on every upload, and you're betting your application on its accuracy.
There's also no shared standard underneath it all. The market is fragmented and system-specific. JSON Resume from jsonresume.org is a community-driven open schema with limited, hard-to-measure employer adoption. Europass is a European Commission CV format, not a global ATS interchange standard. HR-Open Standards LER-RS is an emerging interoperability spec, not a mass-market resume format. schema.org is structured-data markup for discoverability, not a canonical applicant record. And HR-XML mattered historically for HR interoperability but isn't a mainstream resume format in current public evidence. So no single open standard is in broad ATS use today. Everyone parses their own way.
Where machine-readable data removes the guesswork
Now flip the problem. What if you didn't ship a layout for a machine to decode? What if you shipped the structured data directly, and kept a pretty version for humans?
That's the idea behind cv.json, the open CV standard from FreeCV. Here's the definition worth keeping: cv.json is one open, MIT-licensed JSON file, published at a stable URL like livelink.cv/ashley/cv.json, that carries your resume as structured, machine-readable data instead of a layout a parser has to guess at.
Instead of hoping a parser extracts your job title from spacing and bold text, you state it as a field. There's no reading-order ambiguity, no header-region mystery, no table to flatten. The data is the data.
What it looks like
A minimal cv.json needs only two sections, basics and meta. Everything else is optional and additive.
{
"basics": {
"name": "Ashley Carter",
"label": "Senior Backend Engineer",
"email": "hidden-by-default",
"location": { "city": "Berlin", "countryCode": "DE" }
},
"meta": {
"version": "1.2.2",
"canonical": "https://livelink.cv/ashley/cv.json"
}
}
Note two things. The contact details are hidden by default, so publishing your CV as data doesn't mean spraying your email across the open web. And meta.version plus meta.canonical tell any reader which spec version this is and where the authoritative copy lives.
Adding the parts an ATS cares about
The fields map to exactly the things a parser is trying so hard to reconstruct: work, education, skills, projects, languages, certificates, plus an availability block and that meta block. Here's a work entry and a skills list as explicit, unambiguous structure.
{
"work": [
{
"name": "Acme Cloud",
"position": "Senior Backend Engineer",
"startDate": "2021-03",
"endDate": "2024-11",
"highlights": [
"Cut median API latency from 480ms to 110ms",
"Led migration of 40 services to a shared auth layer"
]
}
],
"skills": [
{ "name": "Backend", "keywords": ["Go", "PostgreSQL", "Redis", "gRPC"] }
]
}
No table to collapse. No reading order to scramble. A machine reading this knows the position is Senior Backend Engineer at Acme Cloud, from March 2021 to November 2024, full stop. The dates are ISO formatted, so tenure math is trivial and consistent. That's the difference between stating your data and hoping it's inferred.
Compare it directly to that flattened sidebar wreck from earlier. The same "Redis" skill that drifted next to a job title now sits inside a keywords array attached to a named skill group. The same dates that got split now sit in startDate and endDate fields glued to their job. There is no spacing to misread, because nothing depends on spacing.
Education and certificates, stated not inferred
The same logic carries to the blocks people most often mangle on a layout resume. Degrees stuck in a sidebar, certification dates crammed into a margin column, these all become plain fields.
{
"education": [
{
"institution": "TU Berlin",
"studyType": "BSc",
"area": "Computer Science",
"startDate": "2014-09",
"endDate": "2018-07"
}
],
"certificates": [
{
"name": "AWS Certified Solutions Architect",
"date": "2023-05",
"issuer": "Amazon Web Services"
}
]
}
An issuer is an issuer, a date is a date, and a study type is a study type. A matching engine that wants candidates with an AWS certification earned in the last two years can read that straight off the field instead of trying to decide whether "AWS SA Assoc '23" in a footer means what it thinks it means.
The open-to-work block
The availability section carries hiring-relevant signals that a normal resume hides between the lines: whether you're open to work, which roles you want, what work type suits you, and your visa or sponsorship situation.
{
"availability": {
"openToWork": true,
"roles": ["Backend Engineer", "Platform Engineer"],
"workType": ["remote", "hybrid"],
"visa": "EU work authorization, no sponsorship needed"
}
}
This is the part recruiters usually email you to ask about. Putting it in a field means an AI recruiter or matching engine can read it directly. cv.json is designed for AI recruiters and ATS to read, which is honestly where hiring is heading, even if no specific named vendor consumes it today.
How a machine finds it
A file is only useful if readers can discover it. cv.json defines three discovery paths so a crawler or agent doesn't have to guess:
- A
<link rel="alternate" type="application/json">tag in your portfolio page head, pointing at the file. - A
/.well-known/cv.jsonmanifest at a predictable path on your domain. - An
X-CV-VersionHTTP header announcing the spec version on the response.
It also ships with open CORS, so a browser-based tool or AI agent can fetch it cross-origin without being blocked. That's the quiet but important bit: the data is meant to be read by software, so the plumbing assumes software will read it.
It plays nice with what exists
cv.json is field-compatible with JSON Resume. So if you already maintain a JSON Resume file, the core fields line up and you're not starting over. The current version is 1.2, the spec is open at github.com/freecvorg/cv-json, and the license is MIT, which means anyone, including any ATS vendor, can implement a reader without asking permission or paying a fee. That permissionlessness is the whole point of a standard.
A layout resume asks the machine to reconstruct your data. A cv.json hands the machine your data and keeps the pretty layout for humans. You stop guessing what got parsed.
What to do right now
You don't have to choose between a human-readable resume and a machine-readable one. Keep both, in the right format for each audience.
- Fix the layout document first. Whatever you submit to a portal today should be a single column, real text, standard headings, no tables, nothing in the header or footer, exported as a text-based PDF or clean DOCX. This is the floor.
- Test the parse. Open your own PDF, select all, copy, and paste into a plain text editor. Read the result top to bottom. If your contact info is missing, your columns are interleaved, or your skills are a jumble, that's roughly what the parser sees. Fix it.
- Publish a cv.json. Put the structured version at a stable URL with the discovery tags wired up, so AI recruiters and future ATS readers can pull clean data instead of decoding a layout.
- Keep the canonical pointer honest. Set
meta.canonicalto the real URL and bumpmeta.versionas the spec moves. One source of truth beats five stale PDF copies floating around inboxes.
The format rules buy you a clean parse today. The structured file buys you a clean read tomorrow, when more of hiring runs through agents that would rather fetch your data than guess at your ink. You can build the layout resume and the cv.json from the same place, free, at https://freecv.org/builder. Make the machine's job boring. Boring is how you get to the human.